When we, humans, perform a task, we consider changes in environments such as objects' arrangement due to interactions with objects and other reasons; e.g., when we find a mug to clean, if it is already clean, we skip cleaning it. But even the state-of-the-art embodied agents often ignore changed environments when performing a task, leading to failure to complete the task, executing unnecessary actions, or fixing the mistake after it was made. Here, we propose Pre-emptive Action Revision by Environmental feeDback (PRED) that allows an embodied agent to revise their action in response to the perceived environmental status before it makes mistakes. We empirically validate PRED and observe that it outperforms the prior art on two challenging benchmarks in the virtual environment, TEACh and ALFRED, by noticeable margins in most metrics, including unseen success rates, with shorter execution time, implying an efficiently behaved agent. Furthermore, we demonstrate the effectiveness of the proposed method with real robot experiments.
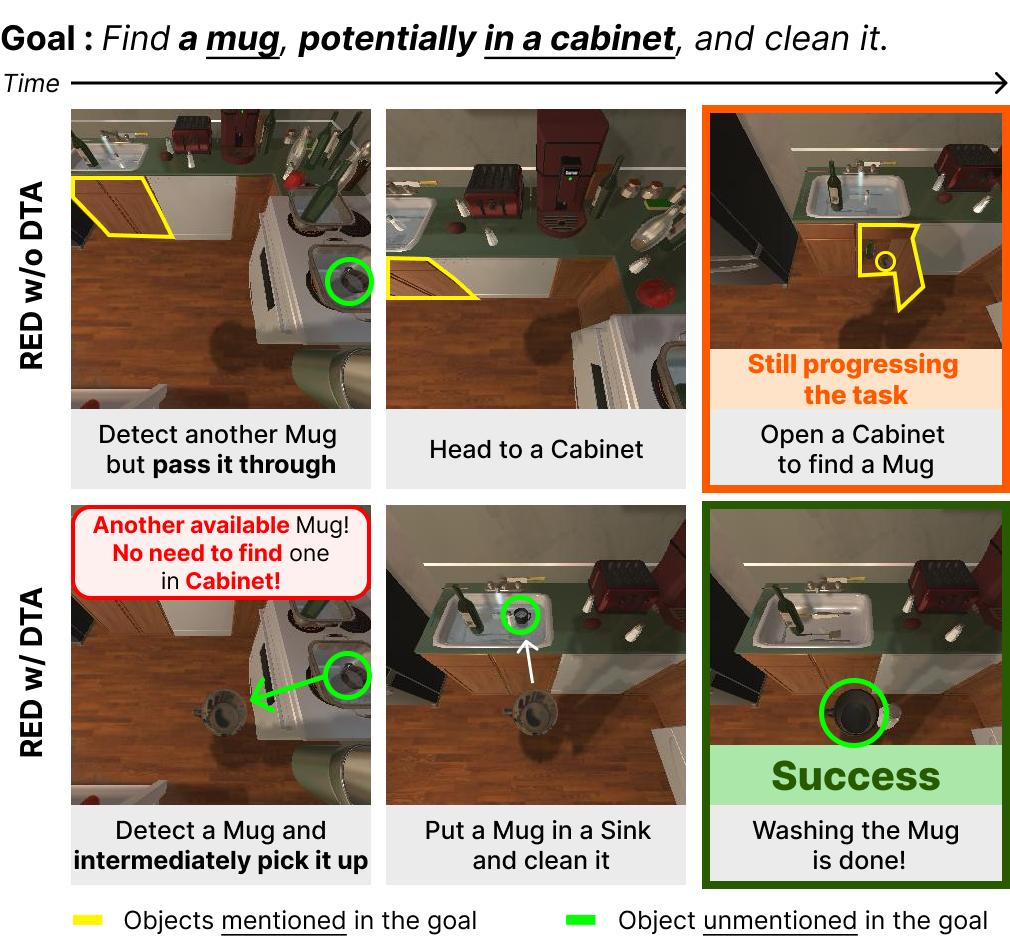
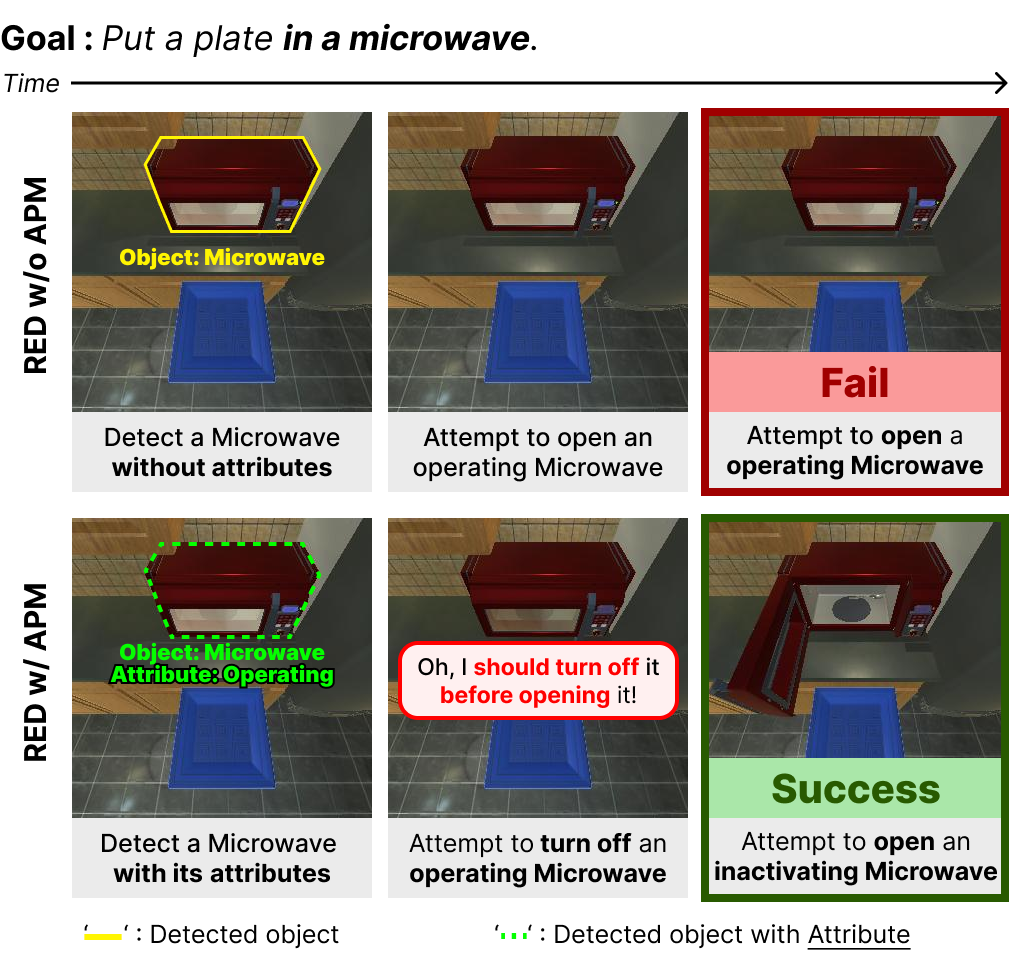
The state-of-the-art embodied agents revise their original plans after taking actions and encountering failures. But failure may result in irreversible consequences e.g., spilling milk on the floor. To address the issue, the agent revises its original action plan before failure based on environmental feedback when unexpected scenarios such as "environmental discrepancies" occur. The system uses a function that generates a revised plan by querying a large language model (LLM) with a feedback prompt describing the discrepancy. Four modules—Dynamic Target Adaptation, Object Heterogeneity Verification, Attribute-Driven Plan Modification, and Action Skipping by Relationship—are proposed to handle different types of discrepancies, improving the agent's ability to adjust its actions effectively.
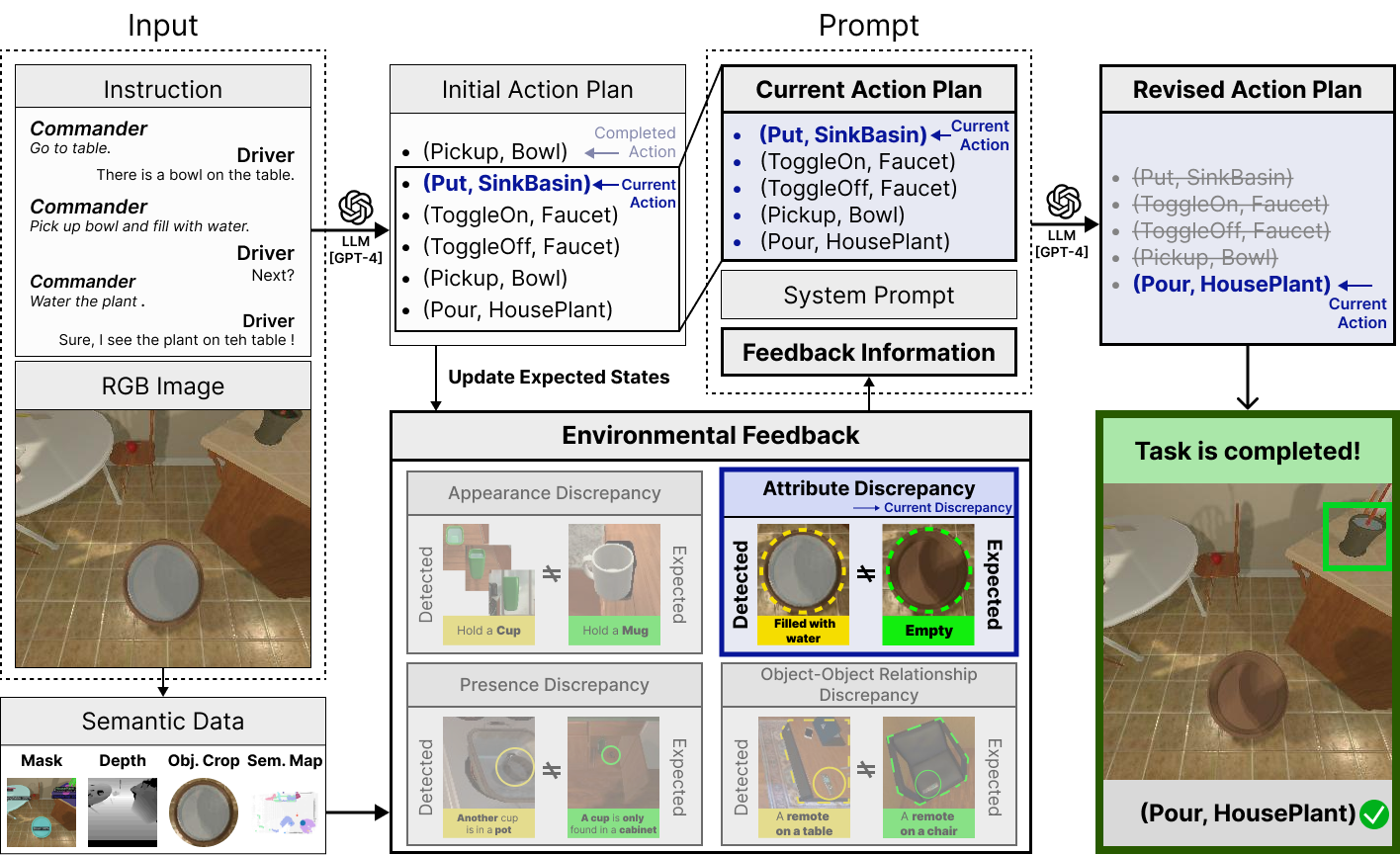


When an agent faces unexpected scenarios caused by 'differences' between inferred and observed states, referred to as 'environmental discrepancies,' PRED revises a original plan, $\{a_n\}_{n=1}^N$, by querying a large language model, \(\mathcal{L}\), with a prompt, \(\mathcal{P}\). \(\mathcal{P}\) concatenates a system prompt, \(\mathcal{P}_{s}\), for a general description and guide of the task, the original plan, and a feedback prompt, \(\mathcal{P}_f\), which describes the discrepancy encountered as environmental feedback generated by the LLM. Then \(\mathcal{L}\) receives \(\mathcal{P}\) and produces a revised plan, $\{a'_k\}_{k=1}^K$ as: \begin{equation} \label{eq:revising_actions} \{a'_k\}_{k=1}^K = \mathcal{L}(\mathcal{P}) \quad \text{where} \quad \mathcal{P}=[\mathcal{P}_{s}; \{a_n\}_{n=1}^N; \mathcal{P}_f]. \end{equation}
Additional details of revising actions are provided in the Appendix C.1. To build a feedback prompt, we consider four types of environmental discrepancies caused by the presence, appearance, attributes, and relationships of objects based on visual information that occupies a large proportion of sensory information perceived by humans.

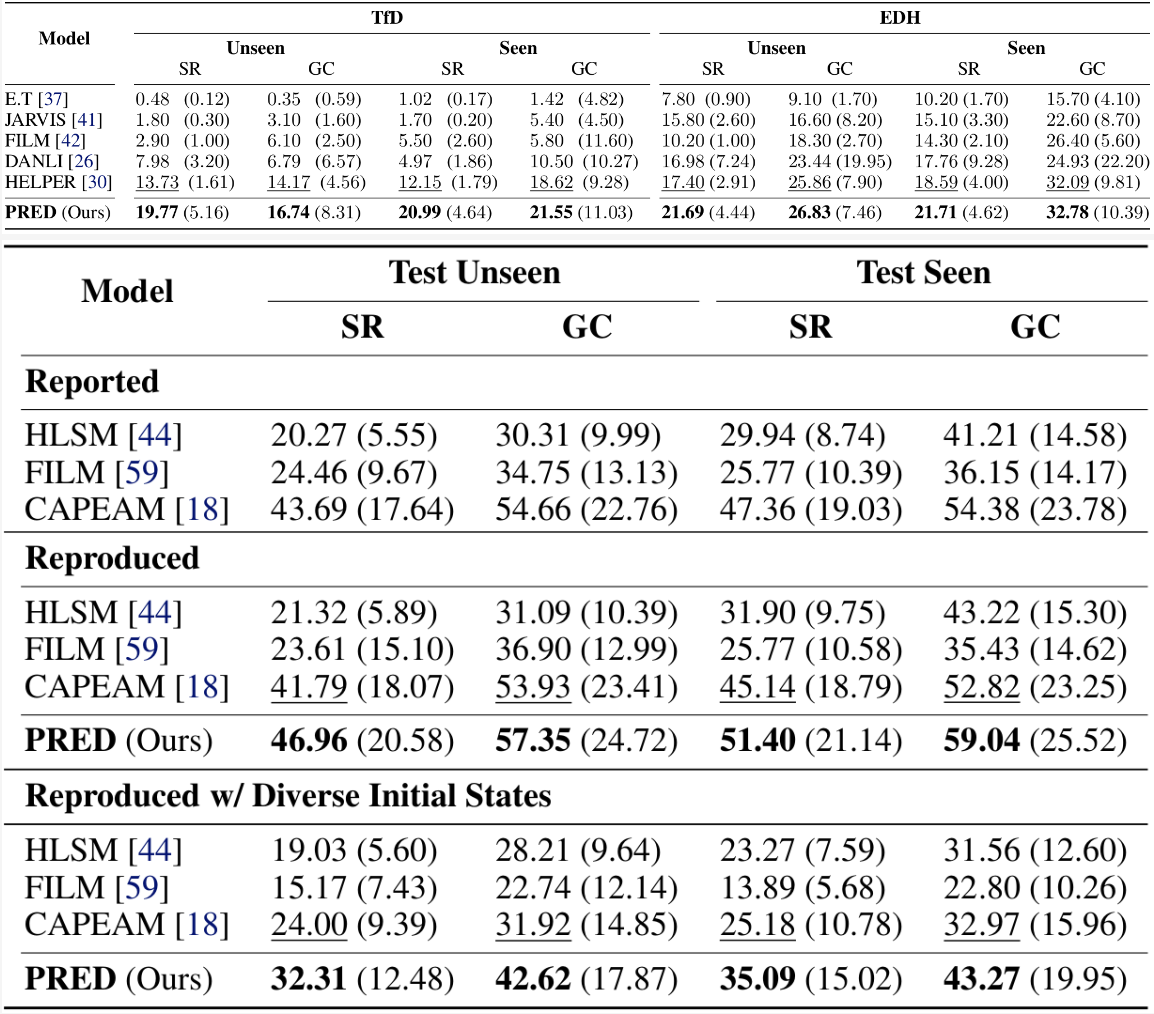
We compare PRED with prior state-of-the-art methods on the TEACh and ALFRED benchmarks summarized in Table 1 and Table 2, respectively. Both benchmarks have three environment splits: 'train,' 'validation,' and 'test.' However, in TEACh, the 'test' split is replaced by 'validation.' The validation and test environments are further divided into two folds, seen and unseen, to assess the generalization capacity. The primary metric is the success rate, denoted by ‘SR,’ which measures the percentage of completed tasks. Another metric is the goal-condition success rate, denoted by ‘GC,’ which measures the percentage of satisfied goal conditions. Finally, path-length-weighted (PLW) scores penalize SR and GC by the length of the actions that the agent takes.
In the TEACh benchmark, in TfD and EDH setups, we observe that PRED outperforms the previous methods in unseen/seen environments for SR and GC, which implies the effectiveness of our proposed PRED. Table 2 shows the prior arts and PRED’s performance in the ALFRED benchmark with a few different settings. We include the ‘Reproduced’ section because the reproduced results of previous methods differ slightly from the originally reported ones. As shown in Table 2, we observe that our method outperforms the prior arts in all metrics, implying the effectiveness of the proposed components.
For more details, please check out the paper.

@inproceedings{kim2023context,
author = {Kim, Jinyeon and Min, Cheolhong and Kim, Byeonghwi and Choi, Jonghyun},
title = {Pre-emptive Action Revision by Environmental Feedback for Embodied Instruction Following Agents},
booktitle = {CoRL},
year = {2024},
}